Методы оптимизации в машинном обучении (курс лекций)/2012/Задание 2
Материал из MachineLearning.
| | Внимание! Текст задания находится в стадии формирования. Просьба не приступать к выполнению задания до тех пор, пока это предупреждение не будет удалено. |
Начало выполнения задания: 27 октября 2012
Срок сдачи: 9 ноября (пятница), 23:59
Среда реализации задания – MATLAB.
Логистическая регрессия
Формулировка метода

Рассматривается задача классификации на два класса. Имеется обучающая выборка , где
— вектор признаков для объекта
, а
— его метка класса. Задача заключается в предсказании метки класса
для объекта, представленного своим вектором признаков
.
В логистической регрессии предсказание метки класса осуществляется по знаку линейной функции:
,
где — некоторые веса. Настройка весов осуществляется путем минимизации следующего регуляризованного критерия:
.
Здесь — задаваемый пользователем параметр регуляризации. Использование регуляризации позволяет снизить вероятность переобучения алгоритма.
Использование радиальных базисных функций

Одним их стандартных способов обобщения логистической регрессии на случай построения нелинейных разделяющих поверхностей является использование т.н. радиальных базисных функций. Здесь решающее правило заменяется на следующее:
.
Здесь базисные функции определяются как
где — параметр, а
— j-ый объект обучающей выборки.
Использование 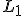 -регуляризации
-регуляризации

Формулировка задания
- Реализовать процедуру обучения логистической регрессии с квадратичной регуляризацией с помощью трех подходов:
- Метод Ньютона с ограниченным шагом (damped Newton) и адаптивным подбором длины шага,
- Метод L-BFGS с подбором длины шага через backtracking,
- Метод на основе верхней оценки Йакколы-Джордана для логистической функции, в котором на этапе решения СЛАУ используется метод сопряженных градиентов;
- Провести тестирование разработанных методов на модельных данных для различных сочетаний количества объектов и признаков, особое внимание при этом необходимо уделить случаю данных большого объема;
- Реализовать процедуру обучения
- Метод покоординатного спуска с подбором длины шага через backtracking,
- Метод с использованием верхней оценки Йаккола-Джордана для логистической функции и квадратичной оценки для функции модуля, в котором на этапе решения СЛАУ используется метод сопряженных градиентов;
- Провести тестирование разработанных методов на модельных данных для различных сочетаний количества объектов и признаков, особое внимание при этом необходимо уделить ситуации, когда число признаков превосходит число объектов, и случаю данных большого объема;
- Написать отчет в формате PDF с описанием всех проведенных исследований. Данный отчет должен содержать, в частности, необходимые формулы для методов с использованием верхних оценок: вид оптимизируемого функционала и формулы пересчета параметров.
Спецификация реализуемых функций
| Минимизация функции с помощью метода Ньютона с ограниченным шагом | ||||||||
|---|---|---|---|---|---|---|---|---|
| [x, f] = min_dampednewton(func, x0, param_name1, param_value1, ...) | ||||||||
| ВХОД | ||||||||
| ||||||||
| ВЫХОД | ||||||||
|
Прототип функции min_lbfgs для минимизации функции с помощью метода L-BFGS выглядит аналогично, 'params' определяет параметры метода backtracking для поиска оптимальной длины шага на очередной итерации. Возможным значением 'params' является вектор из трех чисел [alpha beta rho], где alpha — начальная длина шага, beta — делитель шага, rho — параметр из первого условия Флетчера.
| Обучение логистической регрессии с помощью верхних оценок | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [w, f] = logreg_ub(X, t, lambda, w0, param_name1, param_value1, ...) | |||||||||||||||
| ВХОД | |||||||||||||||
| |||||||||||||||
| ВЫХОД | |||||||||||||||
|
Обратите внимание, что точность решения СЛАУ при использовании метода сопряженных градиентов должна превышать заданную точность eps.
Оформление задания
Выполненный вариант задания необходимо прислать письмом по адресу bayesml@gmail.com с темой «[МОМО12] Задание 2. ФИО». Убедительная просьба присылать выполненное задание только один раз с окончательным вариантом. Новые версии будут рассматриваться только в самом крайнем случае. Также убедительная просьба строго придерживаться заданной выше спецификации реализуемых функций.
Письмо должно содержать:
- PDF-файл с описанием проведенных исследований;
- Файлы min_golden.m, min_quadratic.m, min_cubic.m, min_brent.m, min_fletcher.m;
- Набор вспомогательных файлов при необходимости.
